
VISION
2025/12/19

生成AIの活用が急速に広がる一方、その真価を発揮するために欠かせない「データ整備」が、多くの企業にとって大きな壁となっています。この課題を乗り越えるべく、うるるBPOとLightblueが共同で開発したのが、新サービス「AIブリッジ for Lightblue」です。
▶プレスリリースはこちら
本対談では、両社の代表が、なぜ今AIによるデータ整備が必要とされるのか、その背景にある社会的・技術的課題、そして未来への展望にせまります。

東京大学工学部卒業。東京大学大学院工学系研究科 博士(工学)。修士課程在学中、2018年にLightblue 創業。

1980年北海道生まれ。2006年に代表・星と共にうるるを創業、副社長に就任。クラウドワーカー活用によるBPO事業を立ち上げ、2014年に分社化、うるるBPO代表取締役社長に就任。2015年からCFOも兼任し、2017年にIPOを実現。徳島BPOセンターの開設や、AI×人力のOCRサービス「eas」「eas next」の展開を通じて、DXや障がい者雇用を推進。近年はSaaS導入企業を中心に、導入初期のデータ整備支援を強化し、コンサルから実務まで一貫したBPaaS型支援を提供。生成AIの活用に向けたAI-Readyデータの整備・生成支援でも多数の実績を有し、高い評価を得ている。
目次
園田: Lightblueは2018年創業で、ちょうどGoogleがBERTを発表し、その後のChatGPTなどにつながるトランスフォーマー型AIが登場した時期でした。これまで求人票の自動生成やECサイトの口コミ分析などを手掛けており、当時はパラメータ数や計算リソースに制約があり、生成範囲も限定的でした。それが2022年冬のChatGPT登場を機に状況は一変。2023〜24年にはOpenAIやGoogleのAPIをチューニングして活用できる領域が広がり、RAG(Retrieval Augmented Generation)にも注目が集まりました。
RAG(Retrieval-Augmented Generation):外部データを検索し、得た情報をもとに生成AIが回答を生成する技術。生成AIと情報検索を組み合わせて、より正確な回答を提供。
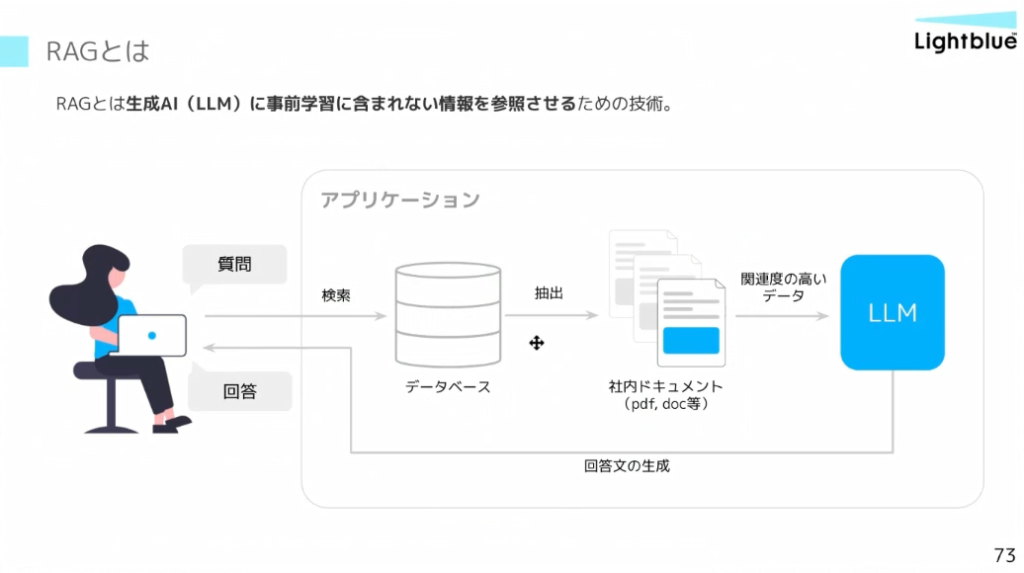
ただ、2024年中頃からは「自社データをどう組み込み、精度を出すか」が大きな課題になったと感じています。特に大企業では活用のルールやデータ利用範囲の整理が進む一方、RAGの精度を左右するデータ整備が不十分なケースが目立ちますね。
当社のワークショップに参加した企業への調査では、業務の約4割で「RAGによるデータベース参照が必要」という結果が出ています。しかし、RAGの導入が“思ったよりうまくいかない”企業が多いのが現状です。その背景には、技術以前の課題が多く存在します。
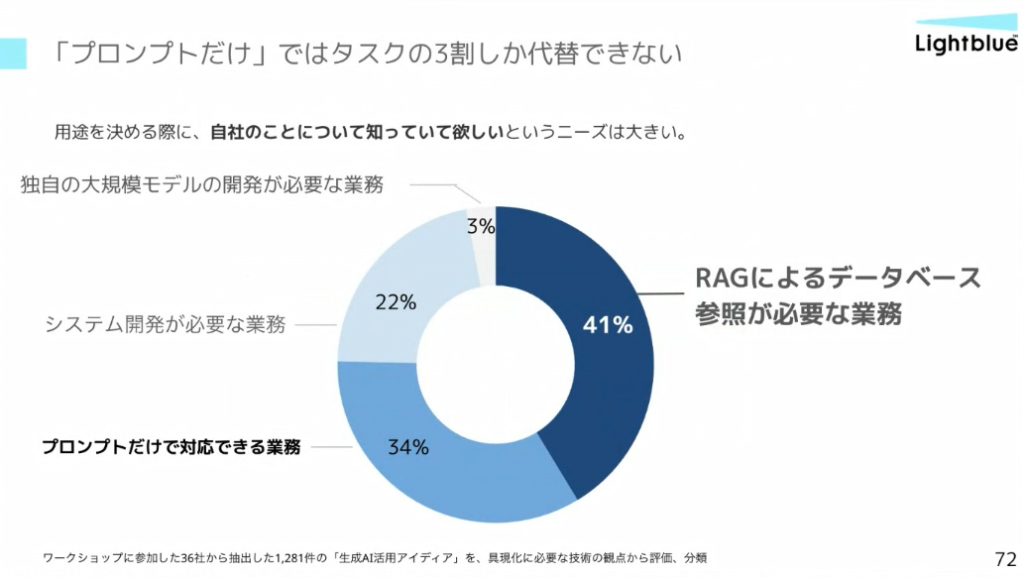
まず、データが紙や画像形式のままで電子化されていない、または文字情報が埋め込まれていないケースが多いです。さらに、活用したい部門とデータ管理部門が分かれており、権限や予算の不明確さから着手できない状況も生じがちです。
桶山: まさにそういった課題に、私たちうるるBPOが長年向き合ってきました。御社のようなテクノロジーに特化した企業が、最終的に「データ整備の壁」にぶつかるというのは、非常に興味深いですね。
園田: そうなんです。データが揃っていても、ログデータや大量の類似マニュアル・仕様書などが混在し、検索対象がノイズだらけになることも精度低下の要因です。差分がわずかな百件以上の仕様書や、整理されていないExcelデータを一括投入することで、検索が的確に機能せず結果の質が下がってしまうんですよね。実際、モデル性能そのものが原因で行き詰まるケースは1割未満で、多くはデータ整備や権限・運用体制といった準備段階での課題が見受けられます。

桶山: そこは私たちの専門領域そのものです。うるるBPOは、RAG導入が失敗する背景にある「データ整備の不在」を専門領域として長年支援してきました。紙資料やPC内に点在するファイルなど、大手企業であっても情報は分散・混在し、管理ルールや方法が不明確なままです。実際、メガバンクの電子化支援では、総務の指示だけでは進まず、事務局として部門長訪問や選択肢提示まで踏み込み、全社を動かしました。

園田: 現場に入り込む伴走型の支援がなければ、大企業の分厚い壁はなかなか破れませんよね。
桶山: おっしゃる通りです。最終的なアウトプットがAIであってもSaaSであっても、根本的にアナログな情報を「使える形」にする旗振り役が不可欠だといっても過言ではありません。大企業ほど歴史的経緯で保存形式が混在し、整理の前提がないため、“現場に入り込む”伴走型支援が必要だと痛感しています。園田さんの言う「壁」に直面する企業は、まずここをクリアする必要がありますね。
園田: 生成AIを業務活用するには、すべてをAIが理解できる状態=「AI-Ready」に整える必要があります。究極のアナログは手書きの紙ですが、これも含め全てAIが扱える状態にしなければなりません。
紙やPDFなどの非構造データは構造化されておらず、特徴量化や質問とのマッチングが困難です。不要情報や欠落も多いため、ユースケースに沿った情報抽出・タグ付け・構造化といった事前加工が不可欠です。これが不十分だと、高度なAIチューニングでも精度は向上しません。
桶山: 私たちも、単にデータをテキスト化するだけではAIが理解できないことを痛感しています。
園田: はい。例えば、企業の資料作成において将来の引き継ぎや検索性を意識して情報を整理する社員はごく少数で、多くは指示された資料を作るだけで「見つけやすさ」まで考慮しません。いわゆるSEO対策として、検索や評価を意識して記事構成をするのと同様に、社内文書もAIに「見つけやすく」しなければならない。業務をAI前提に設計できれば効率化できますが、既存文書の即時改善は困難です。そこで、既存データとAIを橋渡しする重要な役割を担うのが「AIブリッジ」ですよね。
桶山: 人間はビジュアル情報から直感的に理解しますが、AIはそうはいきません。昔からPCがない時代に業務で使われてきた、人間にしか分からないビジュアル資料や感覚的な情報は、AIにとっては「負の遺産」となります。例えば、組織図も画像ではなく「誰の下に誰がいるか」をテキストで記述する必要があります。これらをAIが理解・活用できる形に変換するには、地道なデータ整備作業が必要です。この作業は、園田さんが例えたSEO対策で“検索されやすい記事構造”を作るのと同じ発想で、「機械に正しく読み込まれる」ことを意識して行う必要があります。
非構造データを「AI-Ready」に整えるためのステップは、①スキャンによる画像化②OCRなどでのテキスト化③検索や活用に適した構造化・タグ付けです。

園田: 私たちが提供するサービスも、この③の部分を自動化・効率化する部分に強みがありますが、その前段階の①と②、そして何より③を成功させるための知恵は、うるるBPOさんのような実務ノウハウがなければ成り立ちません。
桶山: 「AI-Ready」は単なるデジタル化でなく、「AIが理解できるようにする」必要があり、これには専門知識が不可欠です。特にプラントや不動産のように、紙資料が多く、専門用語や装置間の関係が暗黙知化している業界では、外部だけでの理解は困難です。そこで、当社は出向社員を含む専門チームを組成し、関連付けやタグ付けを行ってきました。今後も業界ごとのバーティカルな専門チームを強化し、シニア人材やOB・OGの知見をAIに取り込む体制づくりが重要だと考えています。
桶山: 今後は企業規模に関わらず、生成AIが活用できないと生き残れない時代が来ることが予測されます。「AIブリッジ」は、少子高齢化が招く深刻な労働力不足という日本の課題解決に向け、確実に重要な役割を果たす仕組みであることは間違いありません。
しかし経営者は、BPaaS然り、トレンドのツール導入の必要性を感じつつも、着手方法が分からなかったり、導入後も活用されなかったり、という課題が生じる傾向にあります。特に地方や公務員においては、私たちが関わっている最新動向とのギャップが大きく、補助金を使っても成果が出にくいのが現状です。この背景には、生成AIの精度を左右する「AI-Readyデータ」の整備が不十分なことが見受けられます。生成AIの活用を企業に定着させるためには、データ整備や運用設計の支援が“実践フェーズ”のカギだといえますね。
園田: まさにその通りです。補助金が出ても、データ整備まで手が回らず、結果として「使われないAI」になってしまうケースは少なくありません。
桶山: ですから、国や自治体は補助金を通じてAI導入を促進するなら、導入だけでなく活用可能な状態まで整備するコストも対象に含める必要があるのではないでしょうか。そこまでを支援しない限り、実効性は期待できないと考えています。
園田: そうなんですよ。生成AIを業務に根付かせることは、“早い者勝ち”だと言っても過言ではありません。経営トップが、これを“チャンス”と捉えて早く動けるかが非常に重要ですよね。
トップダウンで行うことが効果的ですが、現場からのボトムアップでも、一つのユースケースで高精度を実証できれば活用は広がります。例えば、ある企業では、課長ポジションの方が生成AIの活用性を深く信じ、粘り強く周囲を巻き込んで取り組んだ結果、当初精度30%だった社内RAG検索を97%にまで改善しました。その結果、懐疑的だった役員もヘビーユーザー化したという事例があります。生成AIを一度信じて、全社一丸となりやり切ってみることで、精度が向上する。そして、向上した精度がさらなる信頼を生み、企業への定着を促すのではないでしょうか。
私たちは、今後も「導入ありき」ではなく「活用し続けられる仕組みづくり」に注力していきたいと考えています。
生成AIの業務活用は、ツールを導入するだけでは成果は出ません。精度を左右するのは「AIが理解できるデータ環境=AI-Ready」の整備であり、紙・PDFなどの非構造データや部門ごとに分散した情報を、タグ付けや構造化を通じて活用可能な形に変える“人の手による地道な作業”が不可欠です。
生成AIの活用は、単なる技術導入ではなく業務変革そのものです。特に少子高齢化による労働力不足が深刻化する日本においては、「AIを使える環境不足」の解消が、「人材(労働力)不足」の解決へつながるカギとなります。
私たち「うるるBPO×Lightblue」は、その変革に本気で向き合う伴走者として、これからも企業の生成AI定着に取り組んでいきます。
「AIブリッジ for Lightblue」特設サイトはこちら:https://www.uluru-bpo.jp/aibridge


